Hadoop Installation on Win 10 OS
Setting the Hadoop files prior to Spark installation on Win 10:
1. Ensure that your JAVA_HOME is properly set. A recommended approach here is to navigate to the installed Java folder in Program Files and copy the contents into a new folder
you can locate easily for eg:- C:\Projects\Java.
2. Create a user variable called JAVA_HOME and enter "C:\Projects\Java"
3. Add to the path system variable the following entry: "C:\Projects\Java\Bin;"
4. Create a HADOOP_HOME variable and specify the root path that contains all the Hadoop files for eg:- "C:\Projects\Hadoop"
5. Add to the path variable the bin location for your Hadoop repository: "C:\Projects\Hadoop\bin" <Keeptrack of your Hadoop installs like C:\Projects\Hadoop\2_5_0\bin>
6. Once these variables are set, open command prompt as an administrator and run the following commands to ensure that everything is set correctly:
A] java
B] javac
C] Hadoop
D] Hadoop Version
7. Also ensure your winutils.exe is in the Hadoop bin location.
< Download the same from - https://www.barik.net/archive/2015/01/19/172716/>
8. Also an error might related to the onfiguration location might occur -Add the following to the hadoop-env.cmd file to rectify the issue:
set HADOOP_IDENT_STRING=%USERNAME%
set HADOOP_PREFIX=C:\Projects\Hadoop
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\bin
9. Another issue that I did face while leveraging Hadoop 2.6.0 install was the issue with the hadoop.dll. I had to recompile the source using MS VS to generate the hadoop.dll and pdb files and replaced the hadoop.dll which came along with the install.
10. Another error that I faced was "The system cannot find the batch label specified - nodemanager". Replace all the "\n" characters in the Yarn.cmd file to "\r\n".
11. Also replace the "\n" characters in the Hadoop.cmd file to "\r\n".
12. Yarn-site.xml change is as shown in the screenshot below:

13. Make changes to the core-site.xml as shown in the screenshot below:

14. Make the configuration changes as per the answer here :
http://stackoverflow.com/questions/18630019/running-apache-hadoop-2-1-0-on-windows/23959201#23959201
15. Download Eclipse Helios for your Win OS to generate the jar's required for your map reduce applications. Use jdk1.7.0_71 and not the 1.8+ versions to compile your hadoop mapreduce programs.
16. Kickstart your Hadoop dfs and yarn and add data from any of your data sources and get ready to map reduce the heck out of it.... < A quick note,after formatting your named node it defaults to a tmp folder along with your machine name... in my case it is C:\tmp\hadoop-myPC\dfs\data>
1. Ensure that your JAVA_HOME is properly set. A recommended approach here is to navigate to the installed Java folder in Program Files and copy the contents into a new folder
you can locate easily for eg:- C:\Projects\Java.
2. Create a user variable called JAVA_HOME
3. Add to the path system variable the following entry: "C:\Projects\Java\Bin;"
4. Create a HADOOP_HOME variable and specify the root path that contains all the Hadoop files for eg:- "C:\Projects\Hadoop"
5. Add to the path variable the bin location for your Hadoop repository: "C:\Projects\Hadoop\bin" <Keep
6. Once these variables are set, open command prompt as an administrator and run the following commands to ensure that everything is set correctly:
A] java
B] javac
C] Hadoop
D] Hadoop Version
7. Also ensure your winutils.exe is in the Hadoop bin location.
8. Also an error might related to the onfiguration location might occur -Add the following to the hadoop-env.cmd file to rectify the issue:
set HADOOP_IDENT_STRING=%USERNAME%
set HADOOP_PREFIX=C:\Projects\Hadoop
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\bin
9. Another issue that I did face while leveraging Hadoop 2.6.0 install was the issue with the hadoop.dll. I had to recompile the source using MS VS to generate the hadoop.dll and pdb files and replaced the hadoop.dll which came along with the install.
10. Another error that I faced was "The system cannot find the batch label specified - nodemanager". Replace all the "\n" characters in the Yarn.cmd file to "\r\n".
11. Also replace the "\n" characters in the Hadoop.cmd file to "\r\n".

13. Make changes to the core-site.xml as shown in the screenshot below:

16. Kickstart your Hadoop dfs and yarn and add data from any of your data sources and get ready to map reduce the heck out of it.... < A quick note,after formatting your named node it defaults to a tmp folder along with your machine name... in my case it is C:\tmp\hadoop-myPC\dfs\data>
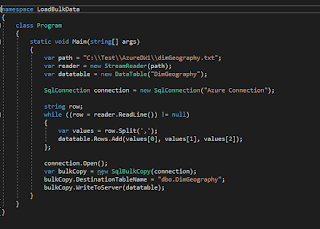
Comments